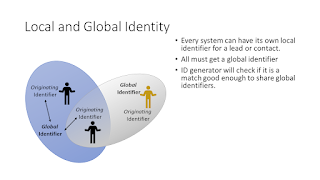
An approach's greatest strength is also often its greatest weakness. You see this in Software Designs or Software Architecture. We design something to be optimized around a set of needs, business functionality, ease of development, ease of maintenance, data integrity, performance. Those decisions create their own problem. We design and build systems optimizing our design around delivery capability, technology, NFRs, and business functions. Those designs and systems architectures take into account the best practices at that time . Those best practices sometimes come from other companies with different priorities and skillsets. The great strengths of your present-day designs will make up a good percentage of the future weaknesses. This should not be a surprise. We design around what we know now and around the technology available at that time. Your successors will toss your design in the future when the strengths of the current approach become the thi...