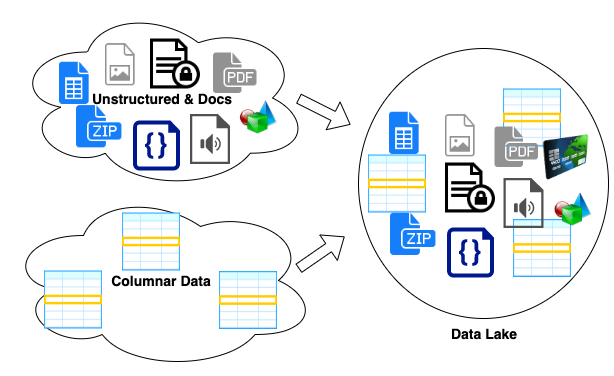
Driving Schema Ownership and Organization

The internet age and cloud competing moved data size, ownership, and privacy to an entirely new level. This is driving organizations to re-thinking where data is moved, how it is transformed, who can see it and, who owns it. Let's talk about how data moves from producer systems through data pipelines and, into Consumable locations with correct access controls. Target State We want to create a well-organized data ecosystem that makes information available to data consumers. The resulting data should be organized for consumers and made available in a way that works with consumer tools. Data starts in source systems owned by applications and organized for the data producer's use cases. The data is extracted from the producer systems in a raw form and stored in a data ingestion zone or data lake. This stage represents the end of the Producer's involvement. The data is converted from producer oriented models to consumption independent models. Traditionally this has been a stan...