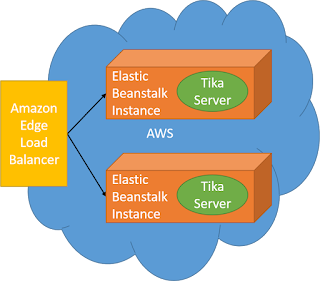
Protecting data in-transit. Encryption Basics

Web traffic is protected in-flight when it is transferred via TLS encrypted links using the HTTPS protocol. HTTPS is a protocol for payload encryption that is based on algorithms using encryption asymmetrical keys. Asymmetrical keys are managed, packaged and distributed with via certificates Encryption Basics Asymmetrical encryption relies on a key pair where one key can decrypt any data that is encrypted by the other. Data encrypted with Key-A can be decrypted with Key-B only. Key-A cannot be used to decrypt data encrypted with Key-A. Key-B cannot be derived by knowing Key-A. Internet encryption relies on asymmetry and key anonymity in order to create secure links over a public and untrusted Internet. A server or party can publish a public key that other parties can use to encrypt their data. The server then can decrypt the message using the corresponding private key . Encrypted messages are secure as long as the server keeps ...