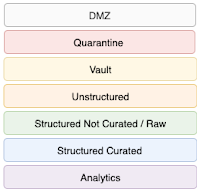
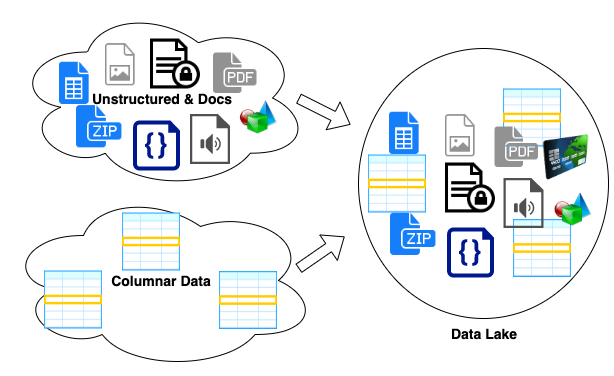
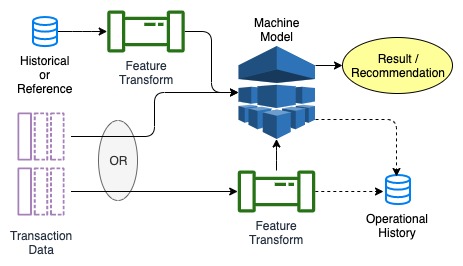
What do you know and why do you know it - Lineage for ML

Process and decision repeatability and accountability is a requirement for large enterprises and entities operated in regulated industries. Machine Learning decision justification and auditability and privacy related data tracking are two areas pushing organizations to improve the way they track data movement, transformation and usage. This drives the need for Data Lineage tracking and reporting. Organizations have to trade off the ease of creating and capturing data lineage, the amount of data captured and the ease of reporting and auditability Data lineage includes the data origin, what happens to it and where it moves over time. [1] Data lineage information includes technical metadata involving data transformations . [2] This diagram shows a simple data movement where data originates in one system, is transformed, stored in a database, then transformed again and used by a machine mode. The re...