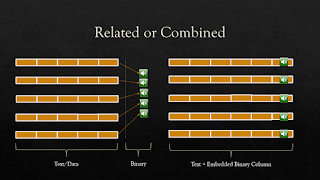
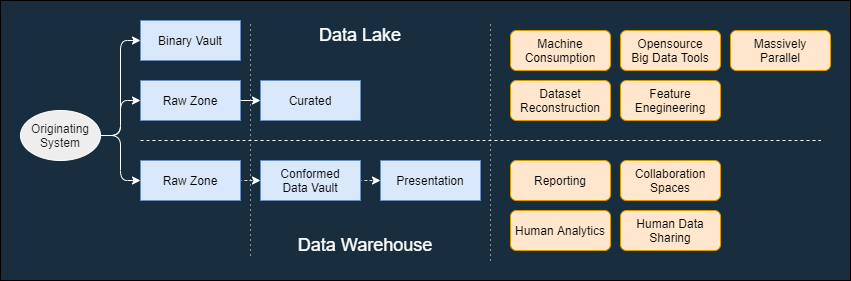
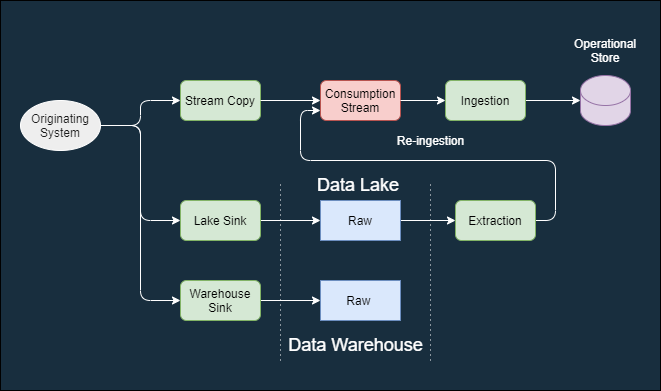
Architectural Decision Records

Create ADRs when making significant and impactful decisions. Retain those decisions in a way that ephemeral media like email, video calls, and IM channels do not. Architectural Decision Records (ADRs) capture architecturally significant decisions or design choices and the context and consequences for the decisions. ADRs exist to help people in the future understand why an approach was selected over others. This includes future you, new team members, and future teams that take over responsibility for systems or processes that were impacted by the ADR. The typical ADR consists of: Components Comment Problem Statement The problem statement that drove the need for an ADR Current Status Draft, approved, declined, etc. Some ADRs will be abandon for other approaches or changes in direction. Alternatives The viable alternatives that were considered and their pros and cons. Decision The chosen solution including enough information ...