Time and Count based Tumbling Windows for Network Packet Statistics
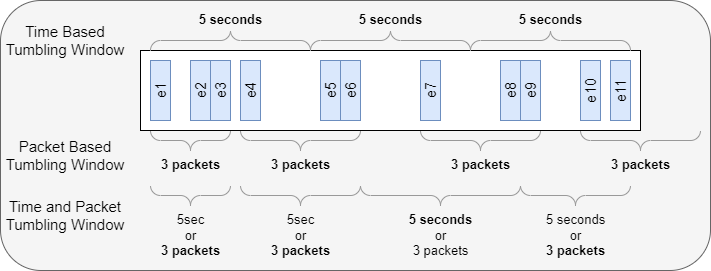
Aggregating and analyzing streaming data is one of the ways people build machine learning datasets. Data is ingested and then data near each other is pushed into aggregations or rows. Aggregations have several attributes or Features . You can think of them as columns in a database or spreadsheet. A data set is made up of many aggregations each one representing some subset of the stream data. You can think of the aggregations as rows in a spreadsheet. One of the challenges is picking the right windowing strategy for aggregating or analyzing streaming data. There are a variety of well-known windowing algorithms, Tumbling, Hoping, Sliding, etc. We are using a Tumbling Windows algorithm because of its relative simplicity and low memory usage. Tumbling windows repeat without overlap. Tumbling windows are either size-limited or time-limited. They contain a maximum amount of data or extend for a maximum amount of time. Time-based windowing: ...