Azure Event Hubs - Namespaces Hubs Schema Registry RBAC
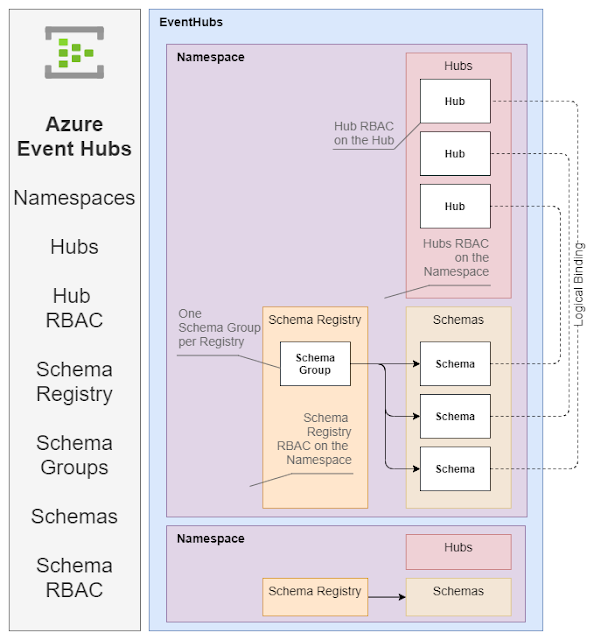
Microsoft has added a Schema Registry to their Azure Event Hubs. This is another feature parity checkbox for those thinking of moving from Kafka to Event Hubs. The Schema Registry at this point feels like it was created by a different team with a slightly different organizational structure and RBAC than that of the Hubs themselves. Schema Registries are useful in a lot of circumstances. Microsoft would have been better served by Making the Schema Registry a stand-alone offering with its own Portal blade. The video below walks through how the Schema Registry is fitted into Event Hubs. Video Speaker Notes Namespaces Namespaces are the Azure EventHubs primary top-level organizational unit. Hub RBAC can be applied at the Namespace level. Schema Registry RBAC can be applied at the Namespace level Hubs Hubs are the individual event streams. They are topics in Kafa terms Access tokens are sup...