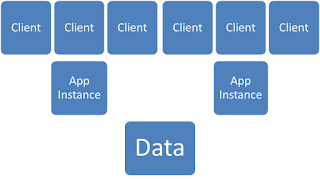
Anti-Affinity for In-Memory Caches or No SQL Data Stores

In-Memory databases and caches, either SQL or no-SQL, are prized for the high performance and high reliability. They scale up by increasing the number of cache nodes to either partition the data for larger data sets or to replicate the data to support more parallel operations. Systems often grow to be hundreds of nodes with some providing almost linear growth versus CPU count. Best practices say to keep duplicate or redundant copies of data in multiple nodes. Disaster Recover (DR) is often integrated through WAN data replication features in the enterprise class versions of these products where data is pushed to alternative data centers. Cluster node management and other configuration concerns can can have a big impact on reliability and performance. Teams should strive to make sure replicated copies of data are as far apart as possible, that they have a low affinity to each other. Teams who are told "you don't care where the serve...