Demonstrating Gemfire Components Configured using spring-data
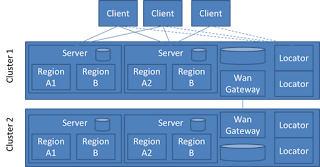
Gemfire, and the applications that use it are made up of serveral components. There is the data caching tier itself that can exist as one or more data nodes. The data tier can be extended to provide database write-behind, write-through and on-demand read-through. The data tier can also be replicated to remote data clusters through the WAN gateway. WAN replication is not currently part of this example. There is also a client tier that can be pure client, client with local caching and notification client or a combination of the three. Client applications can consume data as they would a no-SQL store, database or they can register for data change notifications with the appropriate callback handlers. Gemfire relies on and makes use of other components including the Gemfire locator and JMXAgent. Gemfire clusters will almost always be be coordinated and linked through the use of Gemfire locator processes. JMXAgents add JMX bean access to a gemfire cluster for management and monit...

