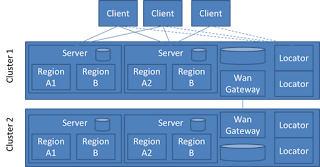
Gemfire, and the applications that use it are made up of serveral components. There is the data caching tier itself
that can exist as one or more data nodes. The data tier can be extended to provide database write-behind, write-through
and on-demand read-through. The data tier can also be replicated to remote data clusters through the WAN gateway.
WAN replication is not currently part of this example. There is also a client tier that can be pure client, client with
local caching and notification client or a combination of the three.
Client applications can consume data as they would a no-SQL store, database or they can register for
data change notifications with the appropriate callback handlers. Gemfire relies on and makes use of other components
including the Gemfire locator and JMXAgent. Gemfire clusters will almost always be be coordinated and linked through
the use of Gemfire locator processes. JMXAgents add JMX bean access to a gemfire cluster for management and
monitoring through either GFMon or some other JMX monitoring tool.
Demonstration program.
You can access this Gemfire demonstration source on github
https://github.com/freemansoft/fire-samples
Gemfire is a set of Java programs or modules.
Gemfire components can be run in as standalone programs using the scripts included with the Gemfire product download or they
can be run as part of some other executable. This demonstration provides support for running all of the PoC/demonstration
components as part of custom java main() executable or as via a WAR file. The java main() programs provide
a simple testing framework for running inside Eclipse. The WAR files provide a method of deploying Gemfire components
in environments where all Java programs must run from inside a Java Servlet or J2EE container.
Gemfire Components and Functionality
This is a very basic demo of some of VMWare's Gemfire product.
It is demonstrable as both standalone components and as deployable war files.
The following is an incomplete list of demonstrated components.
| Locator |
A locator process that shows how the ports are selected |
| Server Cache nodes |
A standalone data server or clustered server that includes listeners and continuous queries |
| Cache Client |
A standalone client program that has local cache |
| Continuous Query Clients |
A standalone client program that receives call backs when data changes in certain regions |
| WAN Gatway |
A cluster node that could be used to replicate data to another site. It currently logs batch data inserts
and updates as they become available from the cluster nodes. |
| Cache Listener |
A component that runs in the server that logs listener events |
| Cache Loader |
Two examples, one that just logs when there is a cache miss and the other that is configured to load cache misses
form the demo H2 database. |
| Cache Writer (write-through) |
Two examples, one that just logs when data changes in the cache and can be written some backend system.
The other is configured to write to a DB when data is saved. |
| Replicated regions |
Gemfire regions where the data is replicated across all nodes |
| JmxAgent |
A JMXAgent wrapper that lets it be run in the same way as the other components. |
| Disk write-through persistence(?) |
One of the regions is configured for disk based persistence |
| Disk write-behind |
hooks demonstrated via WAN gateway and a wan gateway listener |
| The @cacheable annotation |
One of the commands and regions is dedicated the @cacheable annotation. See the "power" command |
| Spring Batch |
Used to load data files and to auto-map flat entities to the backing H2 database. |
Some things that are not yet in the demonstration
- WAN Gateway Basic Spring-Data-Gemfire configuration for a WAN gateway that is used, in this case, to log activity.
- Database Write-behind
This is built on top of WAN gateway. The demonstration includes logging mostly because I couldn't use spring batch to do no code writes they way I could do reads
- Database Write-through
The demonstration includes logging write-through. It will eventually have fully functional write-through
- Partitioned regions This requires that users run at least two nodes to be useful.
- Co-located data in queries These make use of data whose node location is picked based on its relationship to other data.
All regions are currently fully replicated without any partioning.
- Security hooks TBA
- Data morphing based on permissions This is dependent on identity management.
- Index based queries
Queries on indicies with logging to show that Gemfire can search without deserializing the data on the server nodes.
- Properties/meta-data region
An example of how gemfire can use gemfire itself to store cluster behavior information for java proceedures or listeners.
Demonstration Components
Shell
The demo has a lightweight menu system available on stdin/stdout/log4j when running as standalone applications.
The commands are available in both client or server processes.
This provides simple way to muck around with Gemfire features without building your own application.
See the menu in the individual programs for the current list of available commands.
That command line lets you do the following functions:
| Save a note to the notes table. Saves a command line entered note to the NOTES-REGION-WITH-GATEWAY
table which is hooked to an asynchronous listener via the WAN gateway. |
Usage: <cmd> <double quoted message> |
| Generate 2^n as a demo of @Cacheable. Calls a method that calculates 2^n and caches or uses a previously calculated value.
That method is marked with the @Cacheable annotation.
Uses the cache version if you repeat the same number more than once.
Cache entries expire 15 seconds after creation. |
Usage: <cmd> <n> |
| Return Cache sizes for all regions. Clients with local caches return the local cache size |
Usage: <cmd> |
| Create random data and stuff into Gemfire Cluster. This creates 400,000 rows in all tables |
Usage: <cmd> |
| Load a region from a CSV file (absolute or relative to project root). |
<cmd> <region_name> <csv_file_name> |
| Load data from DB pre-defined automapping assumes 1-1 mapping. Uses the Spring batch auto-binding layer |
<cmd> <region_name> |
| Load all possible regions from data from DB pre-defined automapping assumes 1-1 mapping. Runs one thread per region |
Usage: <cmd> |
| Modify a string attribute. Retrieves the object from the cache and changes its value. |
<cmd> <region_name> <pk> <property_name> <attribute_name> |
| Retrieve entire cacheName and show the first entries (requires template). Calls toString()
| <cmd> <cacheName> <showRowCount> |
| Retrieve all data in all Regions. Does not display. May run parallel fetch, one per region (uses templates) |
<cmd> |
| Retrieve from cacheName the object specified by key key |
<cmd> <cache_name> <key> |
| Rebalance cache. Only works on data/server node |
<cmd> |
| Set a property in the property region. Ex 'cacheWriterEnable|cacheLoaderEnable' 'true|false'. Useful for testing properties. |
<cmd> <property-name> <new-value> |
| Purge all data from cache: WARNING! |
<cmd> |
| Exit this program without hesitation. Terminates command line programs |
<cmd> |
Executables
The demonstration is made up of several executables that exist as main() programs that can be run from inside Eclipse with
RunAs-->JavaApplication.
Some of these can also be run as standalone java programs with their own bootstrap.
They were wrapped in the demonstraton to provide a common
run interface.
Java application class files containing the main() entry point
exist in demo.vmware.app to make it easier to explore.
These programs are all in the src/main/java/demo/vmware/app folder.
| DB.java |
This is a demonstration database that can be used to test bulk loading and cache-loader code when
there is a cache miss.
Run this first if you have any of the loaders and listeners enabled. |
| Locator.java |
Run this to start your Gemfire locator that is required before any client or server can startup.
This code supports an arbitrary number of locators per machine but is currently configured for 2 through spring wiring. |
| Server.java |
Run this to start a Gemfire server process. You can run multiple copies of this on the same machine.
The caches are configured through spring so you can convert the regions from simple replicated to partitioned though those files.
The demo command menu is available in this process type. |
| JmxAgent.java |
GFMon, the Gemfire monitoring tool, communicates with a cluster via JMX.This program starts the
gemfire/jmx bridge. Run this agent before running gfmon. |
| Client.java |
Clients can be standalone or caching clients. This is a caching client that runs the same command menu
as the server.
Clients should be launched after all the server and services components have been started. |
| ClientCq.java |
This is a standalone non-caching client that registers a continuous query for data changes of a certain type.
Clients should be launched after all the server and services components have been started. |
| WanGatewayWritebehind.java |
This runs a WAN gateway process that records all data that would either be written to a database
as database write-behind or data that would be replicated across the WAN gateway to another data center.
Only the NOTES-REGION-WITH-GATEWAY region is currently configured for this so you must use the "add a note" command in a server
or client to insert data that is sent to this process. |
Server, Client, Locator and JmxAgent can also be run inside container using the separate war files defined in src/main/resources.
The WAR files are built as part of the standard maven build.
Spring Data Gemfire
The entire demonstration is configured using spring-data-gemfire and spring configuration files. They are located in src/main/resources.
No external or custom Gemfire XML configuration files are needed.
| spring-cache-client-core.xml |
Configures the locator and pdx serialization for Gemfire clients. It is shared by both cq and region-only clients. |
| spring-cache-client-cq-only.xml |
Configures the continuous query and callback for the Gemfire CQ client. |
| spring-cache-client-region-only.xml |
Configures the client cache regions for the Gemfire client application. Adds support for multiple clients on same machine. |
| spring-cache-gateway-writebehind.xml |
Configures the WAN gateway for a single replicated region, in this case to simulate write-behind. |
| spring-cache-jmxagent.xml |
Wires the JMX agent into the wrapper so we can run it as a java application without using the Gemfire supplied scripts |
| spring-cache-locator.xml |
Configures a Gemfire locator service including support for running multiple locators on the same machine. |
| spring-cache-server.xml |
Configures the Gemfire locator service including multiple nodes on the same machine. Defines all the server regions |
| spring-cache-templates.xml |
Defines Spring-data-gemfire cache templates. These act as cache (brand) agnostic proxies and support data insert and retrieval. |
| spring-cache-command-processor.xml |
Configures the stdin/stdout command processor that is available in demonstration clients and servers. |
| spring-cache-datasync.xml |
Creates the mappings for Gemfire Region and database table synchronizatoin. Used by the spring batch framework that the demonstration leverages for some I/O |
| spring-cache-db.xml |
Configures the H2 database connection |
| spring-cache-pdx-serializer |
Enables pdx serialization as the object serialization model. |
Quick-Start Build & Demo
Logging levels are set in log4j.properties.
Logging level changes require a restart to be picked up.
Note: The demonstration programs can be run from inside Eclipse.
Server and Client executables have command interpreters embedded in them.
You can view and enter commands for them in the Eclipse console panes.
Demonstrate basic cache server functionality
- Download the code from github https://github.com/freemansoft/fire-samples
- Run mvn clean install to pull down all the dependencies and to build the class files and war packages.
You will not be deploying the war packages as part of this quick-start.
- Start the H2 database using DB.java. This acts as the read/write-through database for one of the Gemfire regions.
The database optional if you disable or remove the database connected cache loaders.
- Connect to H2 on http://localhost:8082 with your browser. Use the default H2 username (sa) and password (sa).
This can be done from inside Eclipse
- Paste the contents of src/test/resources/sql/create-tables.sql into the H2 command window and execute it.
This creates the schema and loads a couple rows of test data. You could add 100s or 1000s of rows in the sql file to increase the DB size
- Start a Gemfire locator instance using Locator.java. This can be done from inside Eclipse using runAs Java Application.
You can run more than one Gemfire Locator on the same machine. The startup code will automatically bind to an unused port for each instance
- Start a Gemfire server using Server.java. This can be done from inside Eclipse runAs Java Application.
Run the Server.java with larger memory settings if you're going to want to load big data in one of the steps down below.
You can run more than one Gemfire server on the same machine. The startup code will automatically bind to an unused port for each Server instance.
Load will be distributed across them via the locators.
- Verify the size of each cache using the command console of one of the Server instances. One of the commands prints the region sizes.
They should all have zero elements in them because no cache operations have been processed yet.
Demonstrate databse read/write-through
- Each table in the database backs a region in the cache cluster. Query the database for a key.
Then Request an object in one of the regions by key using a commond in the server console.
The cache loader will fetch one row in before returning it to you.
- Query the region sizes again to see that the region used in the previous operation now has an element in it.
- Copy the contents all of the tables from the database into the cache using the server/command console.
- Verify the size of each cache using the server command console. Several of the caches should now have more than one object in them.
- Look at the server logs to see what happened. The logs may be intermixed with your command output.
If you have more than one server running then you may see the log output on the other server(s) also.
Loading more Data
- Load some data from a csv using the command console. The command asks you for the file name and the table to be loaded.
The path is relative to the eclipse project root so it wold be src/test/resources/datafiles.
The filenames are not exactly the same as the region names so pay attention to that when entering the command.
The companies file loads the ATTIRBUTE table and the relationships file is for the RELATIONSHIP table.
- You can create a 2 million record cache through auto-generate command in the command console.
You will receive an "out of memory" error if you ran the servers with the default memory settings.
- Start a client running Client.java using the Eclipse runAs Java Application. You will have to use the
larger heap settings described in Client.java if you want to pull down big data in the next step.
- You can pull down the 2 million rows down to the client via the command menu. It runs one thread per region about 13 seconds on a 2011 macbook.
- Pull down the content of one of the regions using the command console
and have it print a couple objects using the command options.
Continuous Query
- Start a continuous query (cq) client ClientCq.java using the Eclipse Eclipse RunAs Java Application.
- Modify one of the objects that is being monitored by the cq client and you should see it log the fact that it got a callback.
Wan Gateway
- Start the WAN gateway write-behind process WanGatewayWritebehind.java using the Eclipse RunAs Java Application
The WAN gateway is only bound to the "NOTES-REGION-WITH-GATEWAY". Operations on that region will be logged to the WAN gateway console.
- Create a note using the note command using one of the server (or client) command consoles.
Double quote the notes string to include spaces.
- Watch the logs on the WAN gateway to see the gateway pick up the created note. The WAN gateway is "write-behind" so it
will receive the data after some delay.
Using the Spring @Cacheable
- Find the power 2^n command in the command menu. The command calculates powers of 2 and stores them in the cache where they are purged after 15 seconds
- Run the power of two command with some number, say 3 on one of the servers. Note that the output says "calculating"
- Run the same command within 15 seconds. Note the same results are given without the "calculating" message
- Run the same command after 15 seconds. Not that the same results are given and the output says "calculating."
- Try the same with other numbers.
The cache listener and partitioning behavior can be changed via spring config files in the src/main/resources directory.
You can leave the locator and datbase running across Server and Client restarts.
Data Organization
Gemfire Regions
The gemfire regions exist to demonstrate a couple different ideas and capabilities.
| Data Model Regions |
| These were created for a specific demonstration and have self and cross reference joins that make them less than ideal candidates for partitioning.
Most data models have good breakpoints for partitioning. These regions are replicated across all nodes.
All of the data loading and creation happens in these regions. These are the regions we created GemfireTemplates for.
|
- ATTRIBUTE
- RELATIONSHIP
- ACTIVITYLEGAL
- CONTACT
- TRANSFORM.
|
| Properties regions. |
| These regions act as meta-data for some of cluster-side custom code. This lets us create state that can turn on and off
features in our custom code. They can also be used for applicaton wide properties that might otherwise be pushed to
mulitple file systems or an RDB.
|
|
| "Cache-able" regions. |
| This codebase demonstrates how to use the @Cacheable annotation and how it can be used with gemfire to manage objects.
This is a very easy way to push objects into and out of a cache without knowing the cache exists. All ther
uses of the cache in this codebase "know" about the cache.
The example is very simple only using a single region. Applications could share types of objects in a single region
or they could have one region per object type for these caches.
These tables have a 15 second TTL so entries expire 15 seconds after they are created
|
|
| Regions supporting write-behind activities |
| This region is hooked configured in the WAN gateway so that any notes saved to it are asynchronously logged.
This shows where database persistense code would go if you wanted to do database write-behind. The timeouts
and batch sizes for the WAN gateway are configured in their XML file.
|
- NOTES-REGION-WITH-GATEWAY
|
| Regions for future demonstrations. |
| Other regions exist in the config to show alternate cache configurations including disk-persistent or partitioned regions.
|
|
Data Model
Data model objects exist for the Data Model Regions. The demonstration data model is very simple wit one entity per cache element.
I twas done this way to simplify database write-through and read-through. Demonstration data entities all have single attribute keys.
This isn't a requirement but simplifies the demonstration.
Arbitrary, not necessarily uniform, or primitive data can be stored in the other regions.
The properties region, for instance, could hold serialized objects or complex graphs.
The Properties region only stores/retrives strings in the demo but they could be arbitrary property model objects.
Demonstration data
The example contains three sets of demonstration data
- Sql data that can be loaded into the H2 database. It is located in src/test/resources/sql
- CSV formatted data that can be loaded into tables via the command console in the server or client.
It is located in src/test/resources/datafiles. Data exists for the ATTRIBUTE and RELATIONSHIP regions
- Program generated data is available through the command console. This can generate millions of rows in some of the tables in the server.
The server must be launched with larger than default memory settings if you intend to use the data generator command.
Auto-mapping data and file interaction
To be written






Comments
Post a Comment