ML Dev Ops - Not Traditional Software Development
Machine Learning and Machine Models are the latest wave of change in the software development and business rule industry. We spent the last 20 years continually improving our Software Development Lifecycle resulting in today's Continuous Integration and Continuous Development (CI/CD). Machine Learning, Build and Train and ML DevOps are just different enough that we need to step back and rethink some of our current standards.
Using standard CI/CD hardware and software for ML build and train may not be the right approach.
Feature Creation and Model Development
Feature development and Model training are iterative processes with tens or even hundreds of train/analyze cycles. Data scientists need the flexibility to make rapid changes and the compute support to do these iterations in some reasonable amount of time. Regulators and Model Risk Officers need to to see the data transformations and training data itself understand why a given model comes up with its results.
 |
| Notice the back propagation arrows. |
Features are consumer-ready data that can be directly used by a model. Data Scientists manipulate raw data sets investigating what data may be used by a model. The analyze the features to determine if they should be used as model input. The best environments support ad-hoc data manipulation with large data with enough compute to make this happen in a reasonable about if time.
Model development feeds those training features to the raw model to train it. This process may happen hundreds of times while the Data Scientist or automated training environment tries out different curves or training algorithms. Each model needs to be tied to its training data for later analysis.
Video
Models are Trained with Production Data
Models can only be trained with production or very production like. Data. This means the data scientists and the build system must have action for production data. Model retraining systems must have access to current production data.
CI/CD build systems normally are isolated from production data. Now we want to make it possible for non-production (business function) systems to have access to production data.
ML Build and Train Pipeline
There are subtle differences between the standard CI/CD pipeline and the ML pipeline. ML builds are really training sessions that can take several hours or even days. They are a type of code generator that creates new code via its test plans.
- Feature Calculation and transformation. There is often a hand tuning human query generated phase of this and a phase where the Feature transformations are run in an automated fashion to generate the feature in a repeatable fashion.
- This means we may actually have two different tool-sets, the one for humans and they one for automation
- Model Build and Train. Models need to be trained across many hyper-parameter values to identify the best model. Newer cloud environments automate tuning value calculation by training the model across a range of hyper-parameter values.

CI/CD systems are designed to build, scan, and, test. Build and Train systems manipulate data, access data, and run code that changes the model's behavior They continually repeat the same test with slightly different hyper-parameter values. CICD environments are often not set up to support individual builds that take days. Training uses production data that often contains PII. Build environments are not built or audited around this type of data.
Adjust Model using Production Data
Model retaining is when a model must repeat the build and train cycle because of changes in the underlying data distribution. An example could be changing consumer buying behavior resulting from a pandemic

The ML build and train has to be re-triggered based on that drift. This essentially re-triggers the ML build / train cycle based on changing data. That is a very uncommon CI/CD scenario.
Modern CI/CD Pipelines
CI/CD pipelines create build artifacts. They are similar to but conceptually different from Machine models. Training stages actually loop internally while changing hyper-parameters. Traditional CI/CD has no notion of continually running a build or set of tests while changing traditional values to create a different product based on the test results.
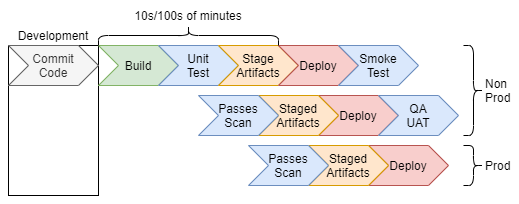
Impact on standard CI/CD systems.
- DevOps pipelines are not designed to have very long-running build jobs.
- They are usually isolated from production data with no permission to see the internals of that data.
- They may not have audit trails or Data Steward data access approval processes.
- Access to build machines is often tightly controlled while the Feature and ML training environments require a fair amount of hands-on access so Data Scientists can explore easily.
- ML training can require large amounts of computing power and often run in parallel requiring even more compute. This means build servers need to get bigger or have network and permission access to specialized hardware.
Standard CI/CD is probably not the optimal build and train environment.
References
I found these after putting together this blog



Comments
Post a Comment