Enabling Microsoft Application Insights for Mule ESB monitoring
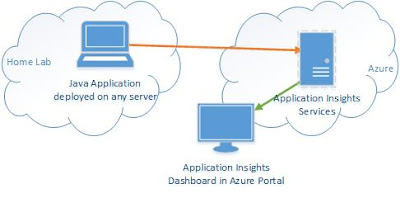
Microsoft Azure Application Insights requires Mule 3.7 or later. Application Insights depends on org.apache httpclient and httpcore versions that are first bundled with Mule 3.7 Application Insights is an Azure based application performance dashboard that can monitor applications deployed inside, or outside, Azure. Application Insights SDKs are available for a variety of languages with a heavy focus on standard library web driven applications or services. This blog entry describes how easy it is to enable Application Insights for a Mule ESB application that does not use any of the out-of-the-box supported web hooks. In this case, we monitoring the out-of-the-box JMX beans provided by Mule. Performance information is gathered by Application Insights where it is displayed in the Azure Portal. Mule exposes performance data about applications and flows via JMX. Any of this can be forwarded to the Application Insights Dashboard. Steps Create an Application Insights...







