DASK so cool - Faster data analytics with Python and DASK - Run locally with Docker
Data scientists and others want to analyze and manipulate lots of data without having to be Software developers. Jupyter notebooks, Python and no DASK are vehicles that help make that happen.
DASK is a distributed Python library that can run in pretty much any Python environment. It was designed to help data scientists scale up their data analysis by providing an easy to use distributed compute API and paradigm. DASK/Python can be run both inside Jupyter notebooks and as standalone Python programs.
DASK is a distributed Python library that can run in pretty much any Python environment. It was designed to help data scientists scale up their data analysis by providing an easy to use distributed compute API and paradigm. DASK/Python can be run both inside Jupyter notebooks and as standalone Python programs.
Environment
The DASK environment consists of a Dask Scheduler and any number of worker nodes. The Python program sends a set of tasks to the Dask Scheduler which then distributes those across the worker nodes. The worker node results are then aggregated and returned to the original program.Docker
The DASK team provides samples how to use docker-compose to create a DASK development and execution environment The environment consists of
- A development node with Python and Jupyter Notebook server
- A DASK scheduler
- DASK worker nodes
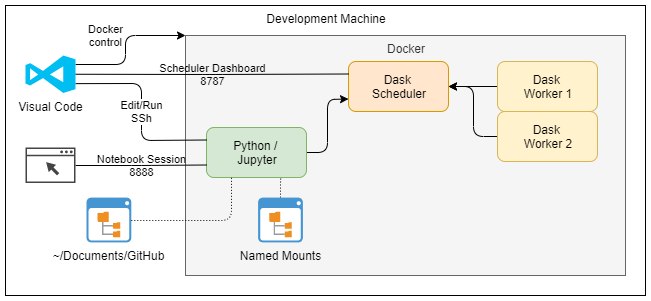 |
| Local DASK docker cluster deployed in Docker |
Quickstart DASK Python Code
See this docker-scripts repository on GitHub.
- Clone the repository,
- cd into dask
- run docker-compose up.
- Run this sample code
from dask.distributed import Client
client = Client('scheduler:8786')
def square(x):
return x ** 2
def neg(x):
return -x
# this will run two different distributed operations A = client.map(square, range(100)) B = client.map(neg, A) total = client.submit(sum, B) total.result() client.gather(A) |
DASK in Action
The demonstration code for the video came from distributed.dask.org quickstart
DASK with Jupyter notebooks running locally on Docker
DASK with VSCode running locally on Docker



Comments
Post a Comment