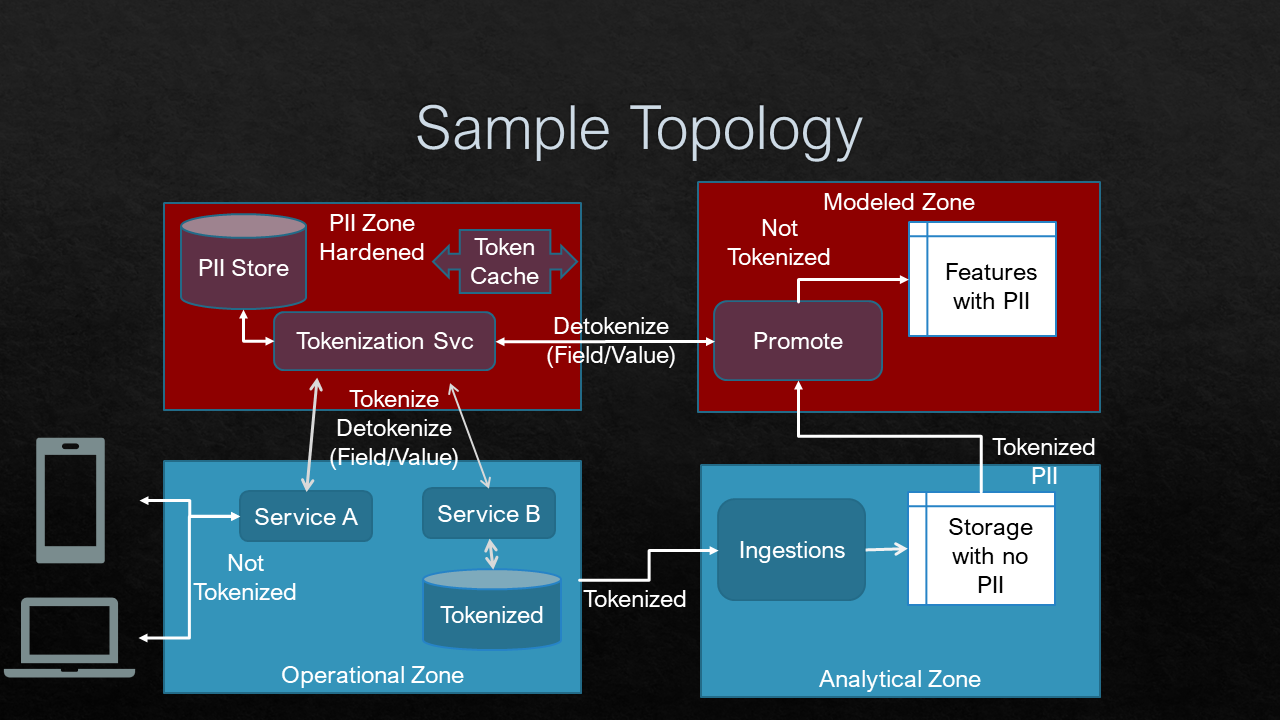
Data tokenization formats and other behavior issues like equality and fidelity.
PII tokenization is a way of protecting Personally Identifiable Information (PII) with similar impacts as field-level encryption but without the overhead of key management or rotation. Tokenization and Encryption both have an impact on data equality checking inside applications and on the fidelity of the data. Plaintext data can be searched and matched us case-sensitive or case-insensitive techniques. Tokenization and Encryption make that impossible because the data is transformed into a form where the case and punctuation are embedded in the data blob. We can transform the data to a canonical form prior to tokenization. That makes equality matches easy but makes it difficult to return the originally formatted value because the token/encryption had to same case or character set prior to tokenization in the source data.
Video Presentation
Slides and Speaker Notes













Comments
Post a Comment