Machine Intelligence Feature Flow
What is a Feature?
A feature is data that has been prepared to be used as input to a Machine mode. The feature can be a data set or scalar value or an aggregation. It is created by transforming, categorizing or aggregating original source data. Features can be created and used in almost any type of application, and can be calculated a priori or calculated as part of model execution.
What is an Enterprise Feature?
ML/AI model usage in regulated industries often includes proof of data lineage used in training the model and in feeding the model in production. The models themselves must often be registered as they are trained and retained for audit purposes. The retained features and retained models can be used later for bias or fraud investigations as part of the normal regulated industry audit process.
An enterprise feature is a feature that meets regulatory, legal and compliance requirements required in regulated industries. Data, and transformation registrations and and models are retained for tracking and audit purposes. Data transformations, original source data lineage and ML models themselves must be approved by the corporate Enterprise Data Protection groups. Some companies have explicit machine learning risk management teams.
An enterprise feature is a feature that meets regulatory, legal and compliance requirements required in regulated industries. Data, and transformation registrations and and models are retained for tracking and audit purposes. Data transformations, original source data lineage and ML models themselves must be approved by the corporate Enterprise Data Protection groups. Some companies have explicit machine learning risk management teams.
How are Features Used?
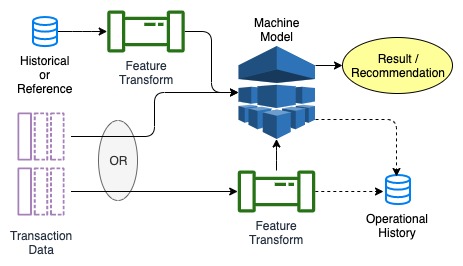 Machine Learning models accept input data in the form of features. They can be pre-calculated possibly in a batch process or calculated on-the-fly in real-time.
Machine Learning models accept input data in the form of features. They can be pre-calculated possibly in a batch process or calculated on-the-fly in real-time. Note that data can sometimes be accepted in raw form by the model. That data is still considered a feature.
Explore, Train, Build Pipeline
Data scientists explore their data and experiment with models using production data. They use an iterative approach as they try different data, transformations, categorizations and model types. Exploratory work often happens in some type of Data Analytics or Production Analytics environment. This lets them use anonymized production data semi-production data controls.
- Transform: Create the reference or semi-static feature data, ex: states to regions. Use some subset of the input data as training data and convert it to feature form. Convert the input data subset used for testing to the feature form
- Train: Run the model against the training feature set and the reference feature set.
- Test: Run the model against the test feature set and the reference feature set
- Evaluate: Verify the expected results
- Iterate: Make changes to the transforms and re-run the process to acquire better results.

Production Progression and Usage
Feature data preparation and usage follows a regular controlled process with full traceability similar to that used for deploying source code. You can think of the features and model as a type of source code with a controlled path to production.
- Transform: Register the transform code that creates the feature for traceability purposes. Deploy the transform and generate the feature for production.
- Register: Save the feature to some secure location or lake. Register the feature and the transform(s) used to create it.
- Discover: Models that are deployed in production use a discovery mechanism to find their feature data. Simple hardwired production code may skip this step instead hard-wiring their feature locations
- Consume: Production code retrieves the previously created feature when running a model and uses it as the model's inputs. This stage should generate metrics that show how the model ran.
- Evaluate: Data scientists often evaluate the results and adjust features to to change the model behavior. They also use production data in the analytics pipeline to rethink feature creation.

Finish
Created 2019/11/07



Comments
Post a Comment