Organizing the Raw Zone - Data straight from the Producers
The right approach for laying down raw data in your data lake or your Cloud Warehouse depends on your goals.
- Are you trying to ensure the data lands exactly as sent for traceability?
- Are you planning on transforming the data to a consumer model to decouple producers and consumers?
- Are you have structure, semistructured, documents, or binaries?
- Do you have PII exposure?

Video
Presentation Slides
This section exists to provide static copies of the material in the video. Additional content may be added over time.
We're talking as if you have a data pipeline that moves data from the producers into locations that are friendly to data consumers. It could be a simple pipeline with just a couple steps or it could be something sophisticated that includes things like DataVault modeling layers. Two main things to think about. Who owns making the data consumable? Are you capable of supporting an ongoing promotion process that converts data from producer schemas to consumer schemas?
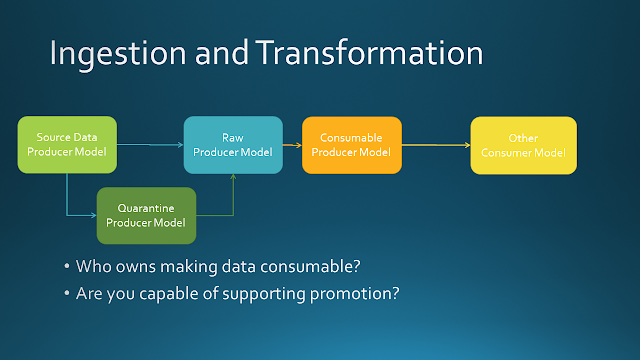
Some organizations just drop the data in their raw zone for others to directly consume. The rest of the slides assume that lake or warehouse data goes through one or more transformations to make it more usable by consumers.
The next decision is to determine if any changes will be applied to incoming data before it is first landed. This decision can be more difficult than it sounds. It takes into account traceability, governance and capabilities.






Blog created 2021/12



Comments
Post a Comment