Explorations: supporting schema drift in consumer schemas
We can merge incompatible schemas in a variety of ways to make a usable consumer-driven schema. A previous blog article described how we should treat and track breaking schema changes. We're are going to look at a couple of ways of merging producer different dataset versions into a single consumer dataset.
A new Conformed dataset with both versions
 |
| Click to Enlarge |
Versioning the records in Conformed
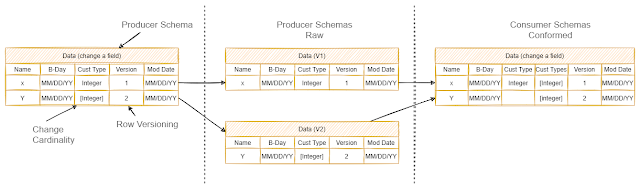
Example: In this example, we change the cardinality of a field. This is a breaking change coming from the source system.
We create new datasets whenever we have breaking schema changes. In this case, we also capture the schema version in each of the raw datasets. That version number may have come with the producer data or it may be added as part of ingestion. You can see two raw zones. One with single cardinality, v1 and one with multiple cardinality v2.
We modify the conformed schema to support both cardinalities and to include the major schema version number. The data catalog tells consumers which columns are valid for each schema version number. Legacy consumers do not break against older data. They must be updated when they want to receive the newer data.
 |
| Click to Enlarge |
We went from single cardinality to multiple cardinalities in this example. In this case, we promoted the single cardinality item into a list containing one element and put it in the multiple cardinality field. This lets us carry data into a breaking change without loss of fidelity.
Video
Related
- https://joe.blog.freemansoft.com/2021/12/schema-drift-when-historical-and.html



Comments
Post a Comment