Cloud and Software Architecture, Soft skills, IOT and embedded
Browsers open extra connections in anticipation of additional requests
Get link
Facebook
X
Pinterest
Email
Other Apps
Browsers can open extra connections or pre-stage open connections to improve the user experience. You can see this if you build your own web server for IoT devices or monitor the connections and not just the requests. These pre-staged connections do not show up in the browser developer tools.
I was troubleshooting a connection timeout issue in a Python-based web server where there were sometimes suspicious connections that timed out. All my testing was done via a browser rather than Postman so I decided to investigate if it was a browser issue or a problem with my service. The developer tools console in Chrome did not show the extra connection in the network traces.
The Python web server generating the logs has a 10-second connection timeout. A single browser action appears to generate two inbound connection requests but only one HTTP request. The 2nd inbound connection appears to be timing out if the user doesn't click on or initiate any additional browser action.
Got a connection from ('127.0.0.1', 64753)
Request Bytes:706
Request Processing: GET/?out_0=off HTTP/1.1
Parameters: {'out_0': 'off'}
Connection closed
Got a connection from ('127.0.0.1', 64754)
Connection closed on error timed out None
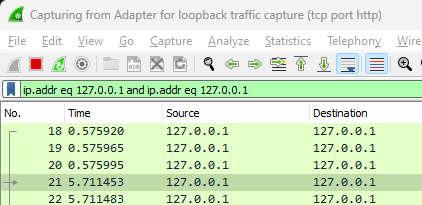
Using Wireshark
Neither the Chrome Browser nor the Edge Browser showed any 2nd connection. I installed Wireshark and set it up to capture inbound traffic on localhost. Then I hit return in the URL bar and saw that two connections were opened to the python server within 5 seconds. This called for more investigation
The HTML contains a markup that causes the browser to not fetch favicon.ico and the trace shows that no favicon.ico request was made.
Chrome: Refresh the URL
This trace shows two sockets opened up when I hit the reload request. The first request is the reloaded HTTP GET on "/". The second request comes about 0.5 seconds after the first. No HTTP request is made on the second socket. The Python code times out the open connection after 10 seconds. You see this around the 10.57 timestamp. Sometime later the Browser attempts to keep the socket open.
Chrome: 2 Button Clicks that both do a GET
This trace shows two sockets opened up when I hit the reload request. The first request is clicking on a link on the page. The second socket opening comes about 0.55 seconds after the first. I then click on a 2nd link about 5 seconds after that and the request is processed on the previously opened socket.
Edge: Retains two open connections
I hit the reload button in edge and ended up with two timeout messages in the logs. Wireshark shows that Edge immediately opens two connections. One services the inbound GET request and the other waits. The inbound requests are processed in about 0.5 seconds like the Chrome numbers above. Edge then opens the 3rd connection so that it has two available. The 2nd connection times out at about the 10-second mark in line with our connection timeout. The 3rd connection times out 10 seconds after that.
Edge: An example of connection staging
This example shows how Edge appears to manage connections across two GET requests. In this case, these were hitting the return key in the URL bar. The browser immediately opens two connections. The first connection handles the GET request. A third connection is opened when the first connection completes. The button on the page generates the GET request around the 4.8 second mark. The python server times out the 3rd connection 10 seconds later at the 14.8 second mark. Then there is some other activity at the 30-second mark, probably the browser timeout.
I do a lot of my development and configuration via ssh into my Raspberry Pi Zero over the RNDIS connection. Some models of the Raspberry PIs can be configured with gadget drivers that let the Raspberry pi emulate different devices when plugged into computers via USB. My favorite gadget is the network profile that makes a Raspberry Pi look like an RNDIS-attached network device. All types of network services travel over an RNDIS device without knowing it is a USB hardware connection. A Raspberry Pi shows up as a Remote NDIS (RNDIS) device when you plug the Pi into a PC or Mac via a USB cable. The gadget in the Windows Device Manager picture shows this RNDIS Gadget connectivity between a Windows machine and a Raspberry Pi. The Problem Windows 11 and Windows 10 no longer auto-installs the RNDIS driver that makes magic happen. Windows recognizes that the Raspberry Pi is some type of generic USB COM device. Manually running W indows Update or Upd...
We have Verizon FIOS with cable TV service. I've never really paid attention to how the Verizon side is wired up until Verizon recently upgraded my FIOS router and tuner box. After breaking my TV tuner by disconnecting an " unneeded" connection, I created yet another diagram of how the FIOS connections work. This is a basic wiring diagram of the house network missing a bunch of devices. Verizon ONT The Verizon optical network terminal converts the optical connection into TV and network standard connections. The ONT is actually two boxes in my situation. One outside connects to the optical and one inside converts something into an Ethernet WAN connection. This results in me connecting a TV COAX and an Ethernet WAN. Verizon TV Tuner The Verizon TV tuner decodes and decrypts TV data that it receives over coax. The TV tuner must talk back to Verizon for any video control operations. It could talk back wireless, over an extra ethernet connection to back over th...
Meetings can be crazy expensive and demoralizing when they burn hours without generating results. Good design sessions, decision-making sessions problem-solving sessions start with the pre-meeting work. An empty meeting invitation is useless and a time drain. Invitees should decline them. A meeting without any context about the problem or prior decisions is going to fail or be way more expensive than it needs to be. Invitees should decline them. Invitations should always state the purpose, contain an agenda, describe the expected decisions that need to be made, and contain background content. Everyone has to do their part. Organizers must meet some minimum bar for meetings to have any value. Attendees must read the invitations and the background materials. There will be super secret projects where no agenda and no supporting information are provided. Those should be the exception rather than the rule. Click to Enlarge Productive meetings have inputs, proces...







Comments
Post a Comment